导语:谷歌近日在 GitHub 页面发布博文,介绍了 VLOGGER AI 模型,用户只需要输入一张肖像照片和一段音频内容,该模型可以让这些人物“动起来”。
3 月 19 日消息,谷歌近日在 GitHub 页面发布博文,介绍了 VLOGGER AI 模型,用户只需要输入一张肖像照片和一段音频内容,该模型可以让这些人物“动起来”,富有面部表情地朗读音频内容。
VLOGGER AI 是一种适用于虚拟肖像的多模态 Diffusion 模型,使用 MENTOR 数据库进行训练,该数据库中包含超过 80 万名人物肖像,以及累计超过 2200 小时的影片,从而让 VLOGGER 生成不同种族、不同年龄、不同穿着、不同姿势的肖像影片。
研究人员表示:“和此前的多模态相比,VLOGGER 的优势在于不需要对每个人进行训练,不依赖于人脸检测和裁剪,可以生成完整的图像(而不仅仅是人脸或嘴唇),并且考虑了广泛的场景(例如可见躯干或不同的主体身份),这些对于正确合成交流的人类至关重要”。
Google 将 VLOGGER 视为迈向“通用聊天机器人”的一步,之后 AI 就可以通过语音、手势和眼神交流以自然的方式与人类互动。
VLOGGER 的应用场景还包括可以用于报告、教育场域和旁白等,也可剪辑既有的影片,如果对影片中的表情不满意就能加以调整。
(文章为作者独立观点,不代表艾瑞网立场)
热门文章

阿里通义千问 Qwen3.8 预览版上线,2.4 万亿参数并官宣将开源
2026/7/20 10:57:11
Anthropic偷偷在Claude Code中植入了隐形代码,只为识别中国用户
2026/7/1 17:09:29
OpenAI提议向特朗普政府提供5%股权
2026/7/2 17:10:24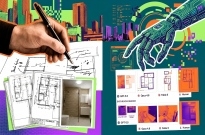
AI 智能体现在能够以专业水准完成 16% 的自由职业任务
2026/7/3 10:46:05
宇树科技科创板 IPO 注册生效,将成 A 股
2026/7/10 9:43:31
字节开始跟你算账了
2026/6/29 16:55:10



扫一扫,或长按识别二维码
关注艾瑞网官方微信公众号

艾瑞网公众号
看资讯、查报告、搜数据 (搜索iresearch21cn或扫描二维码关注)