���
����,��Ϊ��ý������ΨһCCF A�ඥ�������˹�����ѧ������ACM MM 2023���������Ľ�������,�ƴӿƼ��������о��Ŷӵ����ġ�All in One: Exploring Unified Vision-Language Tracking with Multi-Modal Alignment���ɹ���ѡ��
All-in-Oneģ���״�ʵ�����Ӿ�-���Ը�������ṹ��ѧϰ��ʽ�Ĵ�һͳ,�����˸��ӵ��ں�ģ��,ʵ���˸��Ӹ�Ч�Ķ�ģ̬���ٿ�ܡ�All-in-One��4��������ս�Ե����ݼ�(TNL2K, LaSOT, LaSOTExt, WebUAV-3M)��ˢ�������������¼,����OTB99-L���ݼ���ʹ�õ�ģ�ʹﵽ�˶�ģ��Ч��,�����ƴӿƼ����ݴ�ģ���ڶ�ģ̬�������һ�μ���ͻ�ơ�
���ļ��

�Ӿ�-���Ը���(Vision-Language Tracking)�Ǽ�����Ӿ�����Ȼ���Դ�����������һ��������־�����ս�Ե�����������Ҫ������Ȼ������ʾ�ͳ�ʼ�߽�����Ƶ��ȷ��Ԥ��Ŀ����˶��켣,���˻���������Ƶ��ء�������ʵ���Զ���ʻ�����������Ҫ����ҵӦ�ü�ֵ����ȴ�ͳ�Ĵ��Ӿ�Ŀ�����,��ģ̬�Ӿ�-���Ը�����������Ȼ������ʾ,�ܹ����û������������ԵĽ������顣
��ǰ�������Ӿ�-���Ը��ٿ����Ҫ��������ģ��:�Ӿ�������ȡ��������������ȡ�����ں�ģ�顣Ϊ������õ�����,ͨ����������ʹ�ø߶ȶ��ƻ����ӵĵ�ģ̬������ȡ���Ͷ����Ķ�ģ̬�ں�ģ�͡�����,���ַ���������ȡ�Ͷ�ģ̬�ںϵĸ��ٷ�ʽ��������ȡ������ȱ������ָ��������Ŀ���֪������
�����һ����,�����ƴӿƼ��������о��Ŷӵ��о����������һ���Ӿ�-���Ը�������Ĵ�ͳһģ�� All-in-One,��ģ��ֻ��һ��ͳһ�ĹǸ����缴��ͬʱ��ȡ��ѧϰ�Ӿ������Զ�ģ̬������All-in-One�״�ʵ�����Ӿ�-���Ը�������ṹ��ѧϰ��ʽ�Ĵ�һͳ,�����˸��ӵ��ں�ģ��,ʵ���˸��Ӹ�Ч�Ķ�ģ̬���ٿ�ܡ�All-in-One��5��������ս�Ե����ݼ�(OTB99-L, TNL2K, LaSOT, LaSOTExt, WebUAV-3M)��ˢ����State-of-The-Art��
1.���
�Ӿ�-���Ը���(Vision-Language Tracking)�Ƕ�ģ̬��ģ������һ����Ҫ���о�����,�����ܵ��˹�ҵ���ѧ����Ĺ㷺��ע��Ȼ����ȥ������о���Ҫ������˫��(Two-Stream)���Ӿ�-���Ը��ٿ�ܡ��ÿ�ܲ��÷�����Ӿ�������ȡ��������������ȡ��,�Լ�����Ķ�ģ̬�����ں�ģ�顣���ڵķ���ʹ��CNN-Transformer�칹�ںϵĿ�ܡ�����Transformer������,���Transformer-Transformerͬ���ںϵĿ����ʢ�С����й������ڵ���Ҫ������:ʹ�÷����������ȡ���Ͷ���Ķ�ģ̬�����ں�ģ��;���Կ˷���ģ̬�����ֲ����������⡣
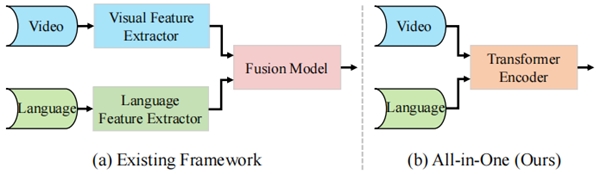
ͼ1 All-in-One��ܺ����п�ܶԱ�ͼ
Ϊ��ʵ��ͳһ��Ч�Ķ�ģ̬������ȡ��ѧϰ,���������һ��ͳһ���Ӿ�-���Ը��ٿ��All-in-One,��ͼ1��ʾ������Ŀ�ܵĺ���˼����ͨ��һ��ͳһ��Transformer�Ǹ����羡������ؽ����Ӿ��������ź�֮���˫����Ϣ����
�����ͳһ���Ӿ�-���Ը��ٿ��All-in-One��������:1)ͳһ�Ľṹ������˫���Ķ�ģ̬���ٿ��,ʵ���˸��Ӹ�Ч�Ķ�ģ̬����ѧϰ��2)�߱���Ϊ��ģ̬�Ӿ�-���Ը������������ģ�͵ľ�DZ�������������ģ�����û�����ĸ�����Ȼ������ʾ��չ�ֳ���ǿ��ķ���������3)��ͨ�õĵ���(One-Stream)�Ӿ�-���Ը����·�ʽ��
����
All-in-One��һ������Ч���Ӿ�-���Ը��ٿ��,������ܹ���ͼ2��ʾ����Ҫ����һ��All-in-One Transformer�Ǹ���������ͬʱ��ȡ��ѧϰ��ģ̬����,һ����ģ̬����ģ�����ڶ����Ӿ��������ź�,һ������ͷ����Ԥ��Ŀ���λ�á�
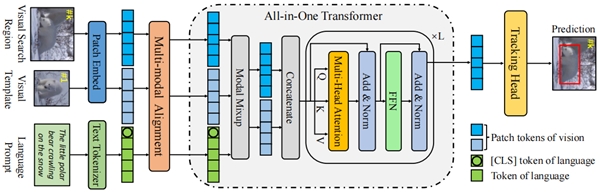
ͼ2 All-in-One�ļܹ�ʾ��ͼ
2.1 All-in-One Transformer���ùǸ�����������Ƕ�����ԭʼ�Ӿ��������źš�����,ԭʼ���Ӿ��������źű�����Ϊ�Ӿ�tokens(��������tokens��ģ��tokens)������tokens����Щtokens������ģ̬����ģ���������ռ��н��ж���,Ȼ���ٴ����Ǹ�����ͬʱ��ȡ�ͽ�ģ��ģ̬������ͳһ�ĹǸ������ܹ������Ӿ�������ģ̬֮���˫����Ϣ��,�����б���Ϣ�Ķ�ʧ,����ģ��֪Ŀ���������
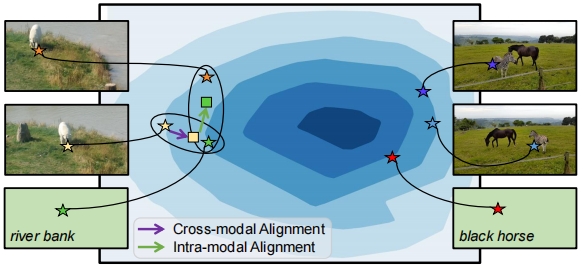
ͼ3 MMAģ��ʾ��ͼ
2.2 ��ģ̬����ģ�顣��ģ̬����ģ��(MMA)��Ҫ���ڽ����ģ̬�����ֲ����������,������ͼ3��ʾ����ģ�����������ģ��:��ģ̬������ģ��(CMA)��ģ̬�ڶ�����ģ��(IMA)��CMA��ģ��ͨ������ƥ����Ӿ�������tokens�������ռ��еľ���,���Ͷ�ģ̬ѧϰ���Ѷȡ�Ȼ��,��������ģ̬��Ķ���,������ģ̬�����õļල�źš�Ϊ��,���ǽ�һ�������IMA��ģ������ѧϰ�Ӿ�ģ̬�ڲ�ʱ������������CMA��IMA��ģ��,����ѧϰ�����Ӻ����Ķ�ģ̬�����ռ�,�ٽ������Ķ�ģ̬��ȡ��ѧϰ���̡�
����
Ϊ����֤��һͳ���Ӿ�-���Ը���ģ��All-in-One����Ч�Ժ�ǿ��ķ�������,������5�����������ݼ��Ͻ�����ȫ������⡣
3.1 ��SOTAģ�͵ıȽ�
���������All-in-Oneģ����TNL2K, LaSOT, LaSOTExt, WebUAV-3M 4�����ݼ���ȡ����SOTA�Ľ����All-in-Oneֻʹ�õ�ģ��,��OTB99-L���ݼ���ȡ���˺�ʹ�ö�ģ�͵�VLT_TT�൱�Ľ������Щʵ����������ģ�͵�All-in-One����ͻ���ĸ������ܺ�ǿ��ķ���������


3.2 ���ڷ���
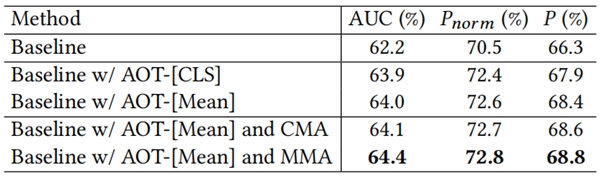
LaSOT���ݼ��ϵ�����ʵ�����,�����ͳһ�ĹǸ�����(AOT)��ģ̬�������ģ��CMA��ģ̬�ڶ�����ģ��IMA���Ա��ĵķ����������ס�
3.3 ���ӻ����
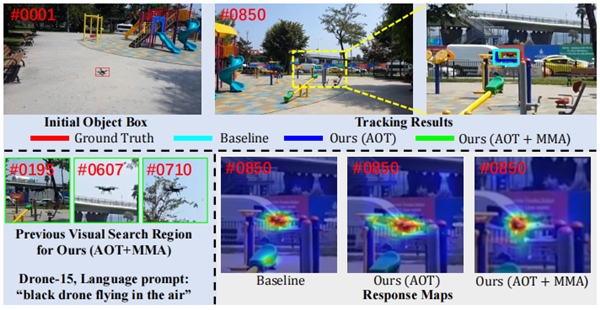
ͨ�����ӻ����ٵ���Ӧͼ,����All-in-Oneģ�;���ǿ���Ŀ���֪������������ʹ��ģ���ܹ��ڸ��ӵı�����������Ȼ����ȷ�ظ���Ŀ�ꡣ
3.4 ���Խ��
���ǽ�All-in-Oneģ�ͺ�����SOTA�ĸ���ģ���ڼ���������ս�Ե���Ƶ�Ͻ����˶��ԵıȽϡ���Щ��ս�Ե����ذ������Ƹ�������ص��ӽDZ仯���������ӡ���۱仯���ڵ��;��ҵĹ��ձ仯�ȡ��������,All-in-One��һ���dz�³���Ķ�ģ̬����ģ�͡�

4.����
���������һ����ӱ���Ӿ�-���Ը��ٿ��All-in-One���ÿ����Ҫ����һ��ͳһ�ĹǸ������һ����Ч�Ķ�ģ̬����ģ�顣���ĵĺ���˼����ͨ��һ��ͳһ�ĹǸ����羡����ڶ���Ķ�ģ̬�ź�֮�佨��˫����Ϣ����All-in-One Transformerʵ����ͳһ�Ķ�ģ̬������ȡ��ѧϰ��MMAģ��ͨ��ģ̬���ģ̬�����������һ���ٽ��˶�ģ̬������ѧϰ���̡�������ʵ��������,�����All-in-Oneģ���ڶ�����ݼ���ȡ����SOTA�Ľ��������Ҫ����,���Ƿ���All-in-One�߱���Ϊ��ģ̬�Ӿ�-���Ը������������ģ�͵ľ�DZ����
��������

��˹�����Ա�꼰�Ϻ������綯��������ˮ��
2024/4/16 14:37:02
9���û�����ֵ300����Ԫ�������ڰ��š�Telegram��������
2024/4/7 16:53:37
ľͷ�㿭�� �� �������Ͷ��OpenAl
2024/4/12 14:32:45
�������� | �й�������籦��ҵ�г���ģ
2024/4/19 10:57:49
����ʲô������������Ǯ�ˣ�
2024/4/7 18:21:49
�������� | �й��ɹ����ֻ�ƽ̨DZ���г��ռ��7000��Ԫ
2024/4/12 10:57:16



ɨһɨ����ʶ���ά��
��ע�������ٷ��Ź��ں�