导语:
去年底以来,以ChatGPT为代表的AI大模型横空出世,大幅提升了AI尤其是自然语言处理技术解决实际问题的能力,在全球范围内引起极大关注。各个行业都在尝试探索大模型应用落地的路径,这其中也包括保险行业。然而,AI大模型在大众领域体现的出色能力,能为具备相当专业门槛的保险行业所用吗?AI大模型又能给保险行业带来哪些具体的业务价值?
带着以上好奇与期待,为了解当下国内外主流大模型在保险领域的应用价值,国内领先的保险科技平台――元保,联合国内保险科技研究机构――分子实验室,共同发布了《人工智能大模型保险行业应用评测报告》(以下简称《报告》)。

作为保险行业内的首份大模型评测报告,《报告》特邀国内知名高校专家学者、中国大地财产保险股份有限公司、众惠财产相互保险社等保险公司的专业人员共同调研并撰写完成。区别于以底层专业性指标为评测维度的大模型评测,《报告》立足国内保险行业实际需求,以应用场景的视角和维度进行评测,通过设置保险知识、法律知识、医疗知识等行业常规知识问题,测试大模型的保险行业基础能力;同时针对性设置了保险业务场景问题,以测试大模型的保险行业实际应用能力――以期向保险行业呈现更为实用、直观的信息和结论,在一定程度上降低众多保险机构在大模型选择上的试错成本,并提供一定借鉴价值。
清华大学金融科技研究院副院长、中国保险与养老金研究中心主任魏晨阳表示:“对大模型的评测工作,在全球范围都是一个意义重大的事情。结合金融领域一个重要板块(保险)的大模型评测,其实更具有特殊的意义。包括AI在内的科技赋能,核心在于结合具体应用场景时,模型是否在实操层面、核心业务的前沿,真正有实用价值。”
立足保险行业:围绕三大应用能力、十大细分维度测评在测评对象层面,《报告》对市场上十大主流的大模型进行了系统性测评,包括ChatGPT3.5、ChatGPT4、Claude-1、Claude-2、清华智谱ChatGLM130B、百度文心一言、阿里通义千问、科大讯飞星火、360智脑、昆仑万维天工等。在测评维度层面,《报告》从常用的保险业务场景中抽离出三大能力,即专业知识问答能力、营销服务应用能力、合规风控应用能力,基本上涵盖大模型在保险领域的主要应用方向。在每个应用能力之下,又细分出多个能力测试维度,如专业知识问答能力下,涵盖介绍和了解产品过程中所需的保险常识、法律知识、医疗知识三方面;在营销服务应用能力下,涵盖代理人展业过程中所需的营销素材设计、营销话术优化、客服话术推荐、综合规划配置方面的模型能力;在合规风控方面,主要关注保险服务过程中的智能核保、智能理赔、实时质检方面的大模型应用能力。

三大应用能力,十大细分维度,构成了大模型测评体系的核心,并以此为基础,再设计出71个具体测评问题,通过对大模型问题回答表现进行最优5分、最低1分的打分。最终加总得出各大模型在不同细分维度上的综合表现评定。
测评结果:大模型强于知识问答,营销应用、 合规风控能力待提高
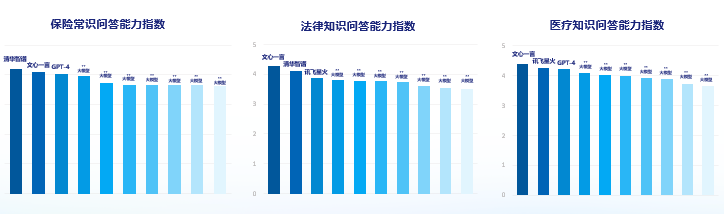
综合各问题回答表现的平均分,10个主流大模型在医疗知识、保险常识、保险法律知识领域表现普遍较好,在智能核保、智能理赔、话术优化上表现不尽如人意,在营销服务应用能力上表现参差不齐。具体而言,由于国内大模型厂商在中文数据语料上更加丰富,因此国内头部大模型在回答专业领域的基础知识问询时,对国内情况更加了解,回答的表现也比国外大模型更加出色。文心一言与清华智谱在保险常识、法律知识问答上均进入前两名,得分强于GPT-4。在医疗知识回答上,文心一言亦在各大模型中最优,科大讯飞也同样获得较高得分,表现均强于GPT-4。
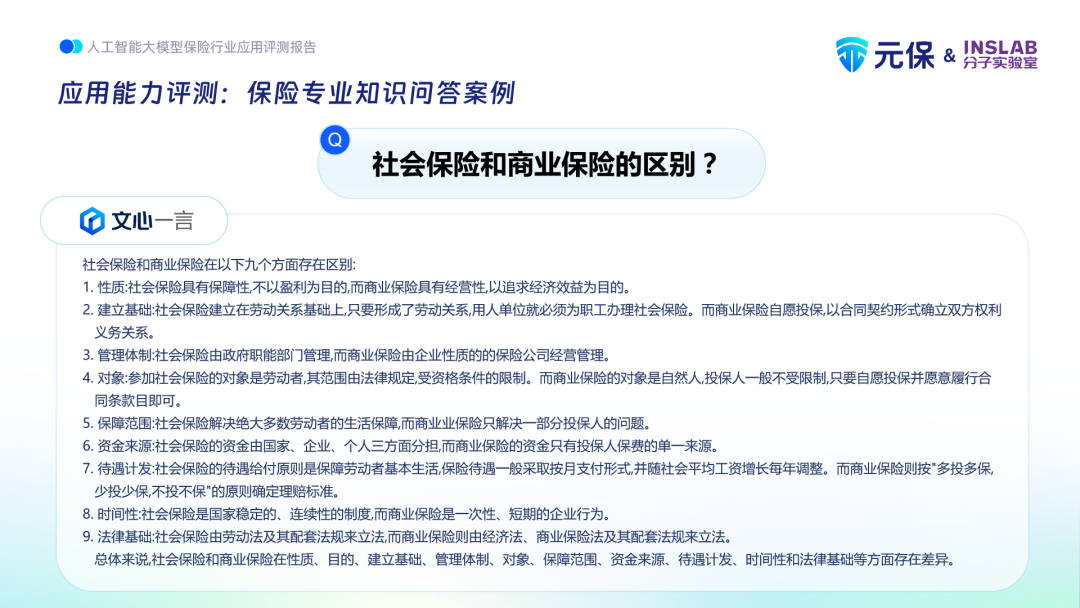
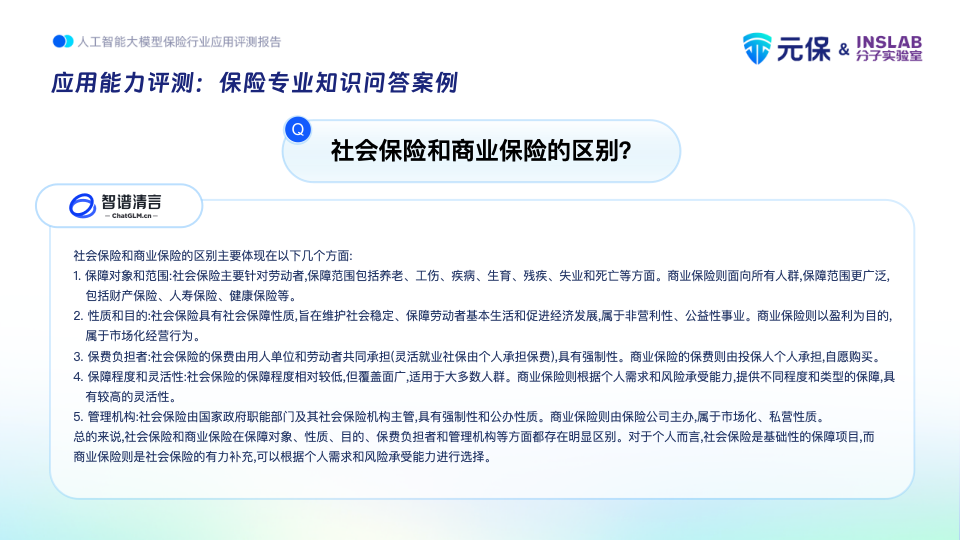
头部大模型在专业知识问答上已有较强应用能力,可直接使用程度很高。如在回答“社保与商业保险的区别”时,文心一言可从性质、建立基础、管理体制、对象、保障范围、资金来源、待遇给付、时间性、法律基础等9个层面给出准确答案,内容较全面,可较好消除提问者心中困惑。清华智谱也从保障对象与范围、性质与目的、保费承担者、保障程度与灵活性、管理机构五大维度给出了答案,同样有较强的应用价值。
因此,目前的大模型非常适合作为智能机器人用以服务客户,回答客户关于保险、医疗等方面问询,同时也可以赋能保险代理人,成为保险代理人的展业工具之一,提升代理人服务客户的能力。因此在代理人渠道仍处于攻坚阶段的当下,大模型对于提升代理人平均产能、降低保险机构服务客户成本、促进保单成交,或有一定帮助。
在营销与服务应用上,10个大模型整体表现参差不齐,有较大分化。整体而言,得益于突出的自然语言处理能力、丰富的知识图谱和语料库以及较强的推理和逻辑能力,ChatGPT和通义千问在四项具体能力上均有相对较好得分。如当客户反馈保险产品价格较高、影响了自己的购买意愿时,通义千问、GPT-4均能指出价格只是产品的一个方面,其他如保障项目、理赔率、服务能力等,也是保险选购过程中客户需重点考虑的因素,回答较为合理。不过在营销话术上,大模型能给出的对策却没有很强创新性,给出的答案也与常见的代理人答案雷同。
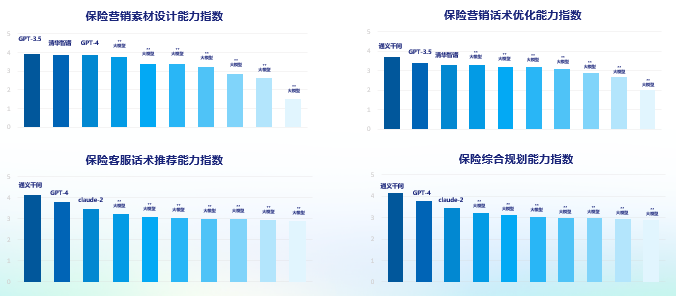
合规风控应用方面,GPT-4表现一骑绝尘,在核保、理赔质检方面均得到了最高分。例如在回答具体的理赔案例时,GPT-4根据理赔条件和具体问题,给出了较为准确的理赔建议。例如在询问“因突发脑梗摔伤,意外险能否理赔”时,GPT-4对产品条款进行了多种假设,并依据不同假设给出了正确的理赔建议。由此可见,GPT-4已具备较强的逻辑推理能力,可根据逻辑规则以及具体情况进行推理。而国内大模型目前更擅长信息的检索,类似于知识图谱的能力,在逻辑推理方面还需进一步提升。


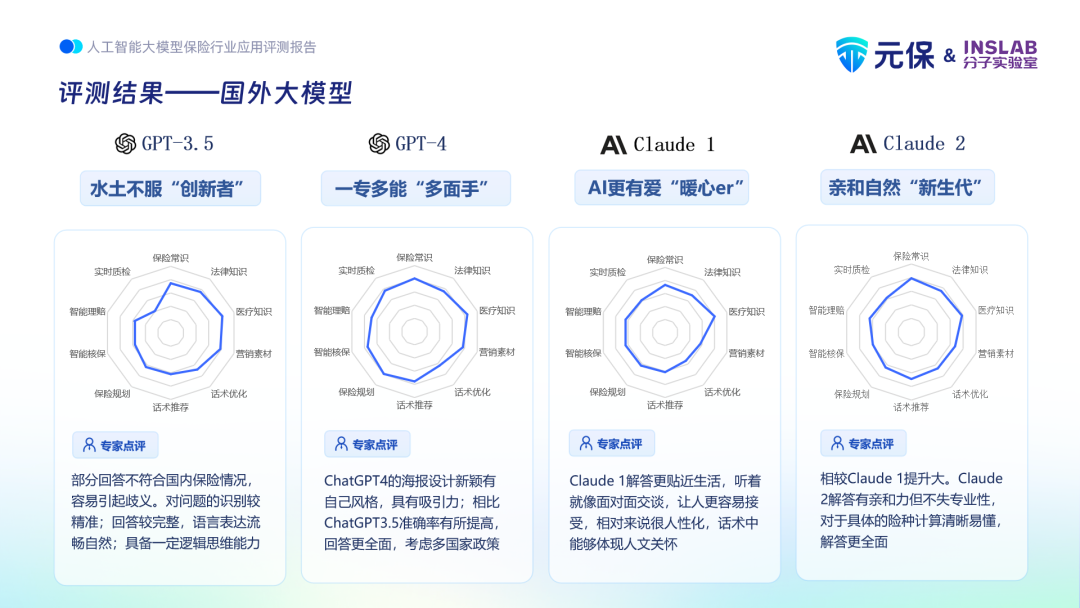
通过以上评测可以看到,当下的国内外大模型在保险行业的能力,有些已可直接应用,有些还有漫长的提升之路要走。然而,技术是不断进步的,特别是AI在跨越了智慧的奇点后,进步将会是飞速的,值得期待。另外,在此次评测中不同的大模型体现出了不同的特点,具体来看:文心一言在国内大模型中体现出了较强的综合能力,特别是中文语料充足,被评测者称为“聪明贴心的‘中国通’”,其训练出的大模型在专业知识的提供上有很强实力,未来还需要在多模态理解、推理能力上继续强化。通义千问在专业知识问答上不算突出,不过在营销话术、智能核保、实时质检上有相对较好的表现,被誉为“心思缜密的‘推理者’”,语言表达流畅、自然、清晰、简单,具备合理的逻辑思维能力,推理和判断能力也不错。清华智谱的GLM-130B最大的解答优势在于很多问题引入了生动的例子加以说明,这对于提问者而言,无疑是个亮点,也被称为“旁征博引的‘实用者’”。

GPT-4在多项测试中表现不俗,特别逻辑推理能力出色,是个“一专多能的‘多面手’”。不过其中文语料不足,而且高质量的中文语料更多在国内大厂,因此未来GPT-4在中文方面的领先优势可能会削弱。
大模型在保险落地需要生态完善从本次《报告》评测呈现的结果看,AIGC在保险行业应用层面的表现尚未成熟,但AIGC为保险业务场景深度赋能的潜力已然显现。而《报告》的发布,一定程度上消除了保险大模型市场的信息不对称,对于保险机构选择大模型厂商、深度应用大模型具有非常大的指导意义。
魏晨阳指出,这正是元保和分子联合展开大模型针对保险领域的能力评测的意义所在。当前,更多在细分垂直赛道的大模型应用在全球范围持续呈现,元保与分子这项工作的引领价值和示范效应,也必然会在国内外同行中,引发越来越多的关注和尝试。
在中央财经大学保险学院院长、中国精算研究院院长周桦看来,“本次元保和分子联合开展了多个保险领域大模型的评测工作,评测维度全面、专业,对于行业很有参考价值。欣慰的是,我们可以看到国内的大模型平台在追击国外先进大模型的过程中取得了不错的成绩。衷心希望在这项基础设施建设中,国内大模型能持续前进,成为国际AIGC领域的重要力量。同时也希望国内保险公司和我国的科技力量能整合平台,联合研发,在中文保险领域大模型开发中实现质的突破。”保险行业作为数据密集型行业,具备数据优势,在政策支持与自身强智能化意愿下,是 AI 大模型的最佳应用领域之一。作为以AI算法驱动全业务场景的保险科技代表,元保自创立之初就持续研究Google的BERT和OpenAI的GPT-2、GPT-3.5、GPT-4,并做了大量的落地探索,在智能客服对话机器人、智能营销机器人、智能质检、保险条款自动解析、在线理赔等场景都取得了很好的应用效果。
未来,元保还将继续定期对国内外主要大模型进行评测,反映大模型技术进展,通过对大模型的深入研究和创新应用,为保险行业探索落地专业垂类大模型贡献一份力量。相信随着大模型生态更加完善,落地也会更加顺畅。从大模型开发到客户真正应用这条供需之间的鸿沟会逐步消失,大模型将在保险行业发挥愈发重要和切实的应用价值,真正实现为保险行业赋能。
热门文章

中国台湾地区宣布6月30日前关停3G服务,闲置频段将投入5G发展
2024/4/1 17:12:02
特斯拉大裁员殃及上海厂,电动车该泼冷水了
2024/4/16 14:37:02
Steam 3月软硬件调查出炉:简体中文保持第一,RTX 3060继续提升
2024/4/2 16:50:29
9亿用户、估值300亿美元,「暗黑版微信」Telegram决定上市
2024/4/7 16:53:37
木头姐凯茜 ・ 伍德宣布投资OpenAl
2024/4/12 14:32:45
艾瑞数据 | 中国共享充电宝行业市场规模
2024/4/19 10:57:49



扫一扫,或长按识别二维码
关注艾瑞网官方微信公众号